利用 百度API进行语音识别 前言 在某次翻墙学习算法的时候,发现了一个学习视频讲的挺不错的,但是没有字幕而且语音是英文,虽然YouTube有翻译的强大功能,现在市场上也有许多软件可以依据视频提取语音文本,但是自己还是想试一试能不能开发出来一个简单的软件。该文主要记录一下自己的学习开发历程。
首先准备 首先是根据需求规划大致开发路线:
最初资源:.MP4
最终需求结果:(有字幕且有译文的).MP4
视频 ——》》》提取音频文件 ——》》》提取文本 ——》》》翻译中文 ——》》》传入视频形成字幕 ——》》》输出视频
具体实现 一、提取音频文件 准备一段长视频(.MP4),创建项目文件。利用ffmpeg 将视频格式文件转换为.wav格式文件。
关于ffmpeg的使用 1 ffmpeg {全局参数} {输入文件参数} -i {输入文件} {输出文件参数} {输出文件}
1 2 3 4 5 6 7 8 9 -c:指定编码器 -c copy:直接复制,不经过重新编码(这样比较快) -c:v:指定视频编码器 -c:a:指定音频编码器 -i:指定输入文件 -an:去除音频流 -vn: 去除视频流 -preset:指定输出的视频质量,会影响文件的生成速度,有以下几个可用的值 ultrafast, superfast, veryfast, faster, fast, medium, slow, slower, veryslow。 -y:不经过确认,输出时直接覆盖同名文件。
常见用法
查看文件信息
查看视频文件的元信息
加入-hide_banner参数可以减少冗余信息的输出,只显示元信息
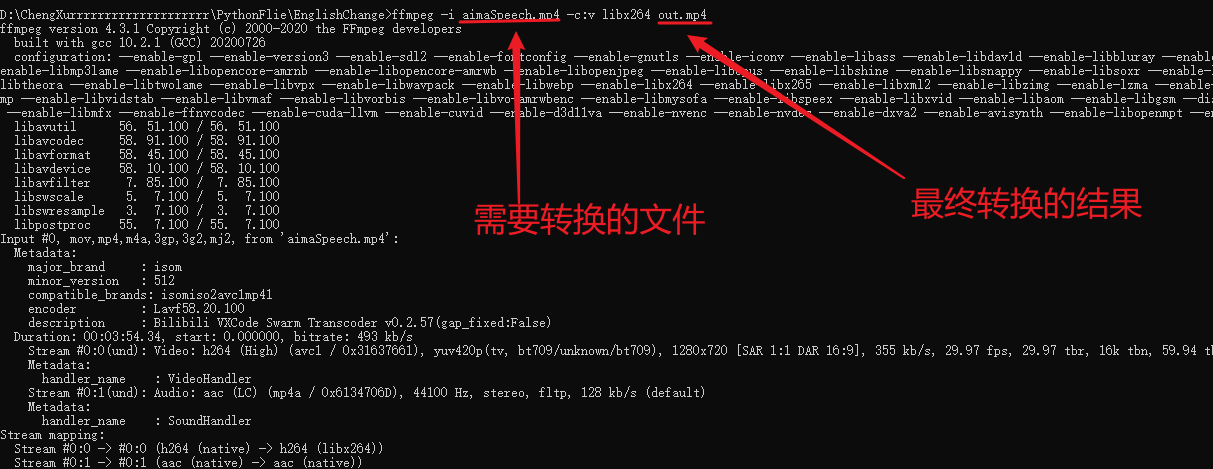
转换编码格式
将视频文件从一种编码转成另一种编码。
1 ffmpeg -i [input.file] -c:v libx264 output.mp4
转换容器格式
将视频文件从一种容器转到另一种容器
1 ffmpeg -i input.mp4 -c copy output.webm
只是转一下容器,内部的编码格式不变,所以使用-c copy指定直接拷贝,不经过转码,这样比较快。
调整码率
改变编码的比特率,一般用来将视频文件的体积变小。
1 ffmpeg -i input.mp4 -minrate 964K -maxrate 3856K -bufsize 2000K output.mp4
( 指定码率最小为964K,最大为3856K,缓冲区大小为 2000K。 )
改变分辨率
从1080p转为480p
1 ffmpeg -i input.mp4 -vf scale=480:-1 output.mp4
提取音频
1 ffmpeg -i input.mp4 -vn -c:a copy output.aac
-vn表示去掉视频,-c:a copy表示不改变音频编码,直接拷贝
1 2 ffmpeg -i {input.mp4} -ac 1 -ar {采样率(16000)} {output.wav} && y
添加音轨
将外部音轨加入视频,比如添加背景音乐活旁白
1 2 ffmpeg -i input.acc -i intput.mp4 output.mp4
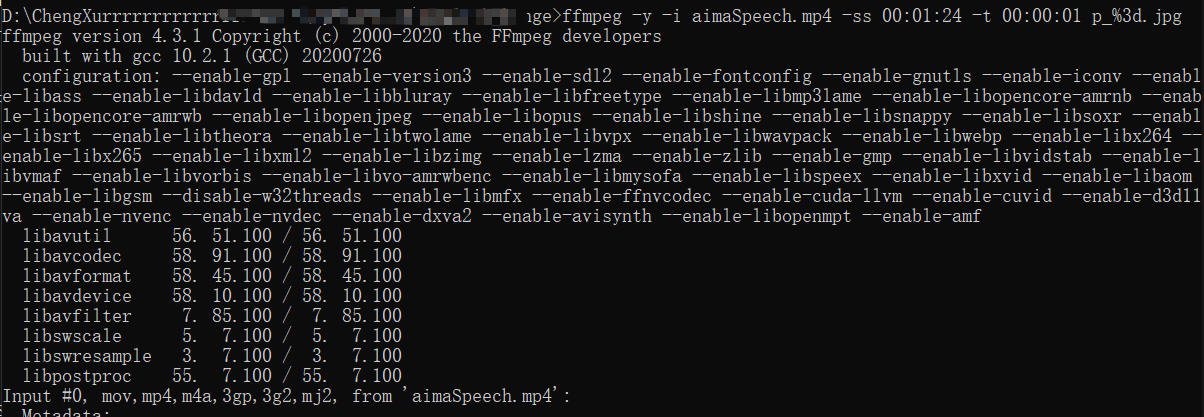
截图
1 2 3 //从指定时间开始,连续对1秒视频进行截图 ffmpeg -y -i input.mp4 -ss 00:01:45 -t 00:00:01 output_%3d.jpg
截图显示:
如果只需要一张截图
1 ffmpeg -ss 00:02:10 -i aimaSpeech.mp4 -y -f image2 -frames:v 1 1.jpg
-vframes 1 表示只取一帧 -q:v 2 表示输出图片的质量,一般是1~5(1的质量最高)
剪裁
截取原始视频里面的一个片段,输出为一个新视频。可以指定开始时间(start)和持续时间(duration),也可以指定结束时间(end)。
1 ffmpeg -ss [start] -i [input] -to [end] -c copy [output]
为音频添加封面
1 2 ffmpeg -loop 1 -i cover.jpg -i input.mp4 -c:v libx264 -c:a aac -b:a 192k -shortest output.mp4
有两个输入文件,一个是封面图片cover.jpg,另一个是音频文件input.mp3。-loop 1参数表示图片无限循环,-shortest参数表示音频文件结束,输出视频就结束。
二、提取文本 我翻阅了多种资料,对于如何实现音频转文本的方法有三种,一种是通过使用 TensorFlow 框架利用模型训练,目前有三种模型HMM 、DNN 和End-to-End 。但是由于该方法写代码耗时长工程量大且目前的训练集不够,因此在当前阶段难以实现。第二种方法是通过利用python自带库“speech_recognition”直接实现语音识别,Speech-Recognition 附带 Google Web Speech API 的默认 API 密钥,可直接使用它。 但是该方法准确度不高, 识别率很低 。最后一种也是本次功能实现的方法就是通过使用科大讯飞API或百度API/(SDK也可以)。
该项目使用的是百度API,这里有一个缺陷就是百度API每次连接只能识别一分钟以内的语音,因此我们需要对长语音进行裁剪缝合处理。
首先先连接百度API,测试实现代码。
先在百度AI开发平台 查看技术文档,查询接口要求。
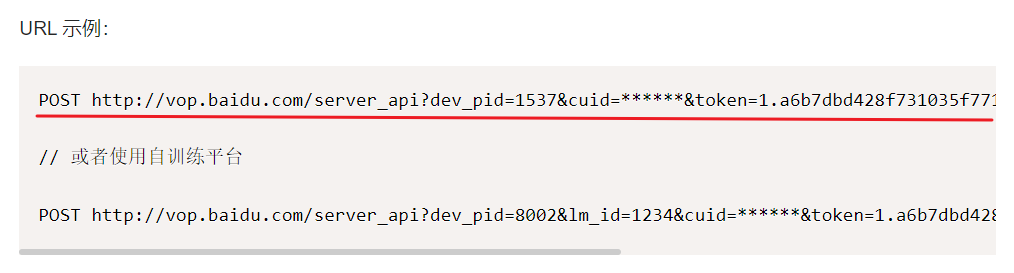
大致使用方法就是,先获取url,设置请求头,发送请求,连接百度语音识别平台传入音频文件,最后获取对应识别结果数据。
代码如下:
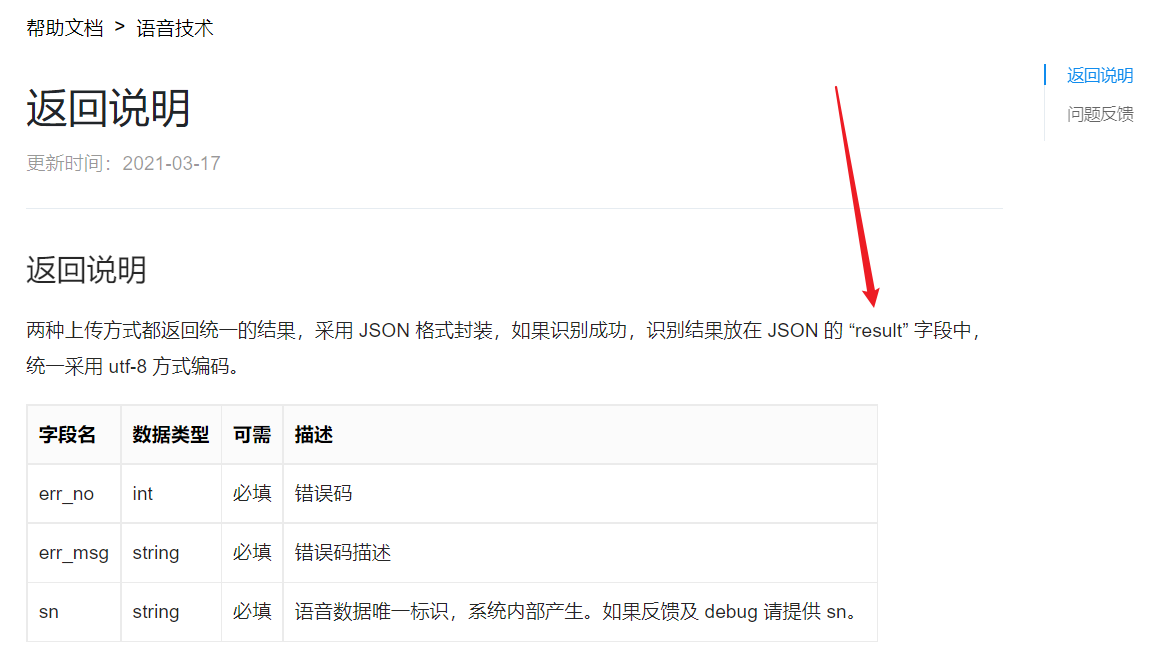
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import jsonfrom urllib import request, parsedef get_token (): API_Key = "VKyf6r*******X" Secret_Key = "Tm****************PfX" Url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + API_Key + "&client_secret=" + Secret_Key try : resp = request.urlopen(Url) result = json.loads(resp.read().decode('utf-8' )) print ("access_token:" , result['access_token' ]) return result['access_token' ] except request.URLError as err: print ('token http response http code : ' + str (err.code)) def main (): token = get_token() speech_data = [] with open ("a2.wav" , 'rb' ) as speech_file: speech_data = speech_file.read() length = len (speech_data) if length == 0 : print ('file 0.wav length read 0 bytes' ) params = {'cuid' : "9E-29-76-BE-C1-98" , 'token' : token, 'dev_pid' : 1737 } params_query = parse.urlencode(params) Url = 'http://vop.baidu.com/server_api' + "?" + params_query headers = { 'Content-Type' : 'audio/wav; rate=16000' , 'Content-Length' : length } req = request.Request(Url, speech_data, headers) res_f = request.urlopen(req) result = json.loads(res_f.read().decode('utf-8' )) print (result) print ("识别结果为:" , result['result' ][0 ]) print (result['result' ]) if __name__ == '__main__' : main()
成功实现完语音识别之后,就可以对音频文件进行处理了。将音频文件分为多个一分钟文件然后多次上传得出数据文本。
· 关于裁剪音频文件的 需要注意的是,如果音频文件时间长度仅仅是除以一分钟的数值会自动四舍五入,这样容易导致音频文件缺失。因此我们需要找到数值的公因数,找到最适宜的数值(使生成文件数量最少最佳)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def getlen (leng ): leng = int (leng) if leng > 60 : dlen = math.sqrt(leng) ilen = int (dlen) while ilen > 1 : if leng % ilen * 1.0 == 0 and ilen < 60 : if ilen >= leng / ilen: return ilen else : return leng / ilen else : ilen = ilen - 1 else : return leng
在百度接口语音识别翻译时,利用遍历剪裁生成的目录进行修改。
最后生成的结果放入txt文本文档。
最后利用百度的文本翻译接口(免费)进行文本翻译实现新的文本文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def translate_api (text ): appid = '202********473' secretKey = '4*****9' myurl = 'http://api.fanyi.baidu.com/api/trans/vip/translate' q = text fromLang = 'en' toLang = 'zh' salt = random.randint(32768 , 65536 ) sign = appid + q + str (salt) + secretKey m1 = md5() m1.update(sign.encode("utf-8" )) sign = m1.hexdigest() myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote( q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str (salt) + '&sign=' + sign return myurl
最后依据以上的过程打包,结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import mathimport reimport BYBaiduapiimport cutwav as swfrom pydub import AudioSegmentimport mp4ChangeWavimport translateByBAIDUdef getlen (leng ): leng = int (leng) if leng > 60 : dlen = math.sqrt(leng) ilen = int (dlen) while ilen > 1 : if leng % ilen * 1.0 == 0 and ilen < 60 : if ilen >= leng / ilen: return ilen else : return leng / ilen else : ilen = ilen - 1 else : return leng if __name__ == '__main__' : interput = input ("请输入需要转化的视频路径:" ) filenames = mp4ChangeWav.getPath(interput) filePath = re.findall(r"(.*?)\.mp4" , interput) wavpath = filenames if interput: second = AudioSegment.from_wav(wavpath).duration_seconds newlength = getlen(second) sw.cut_to_time(interput, filePath[0 ], newlength, wavpath) filePath = BYBaiduapi.dealmain(filePath[0 ]) translateByBAIDU.trans_main(filePath, filePath[0 ]) print ("翻译完成" )
三、结合QT实现界面打包 太菜了,我好累,考完期末再说吧。